Note
Go to the end to download the full example code.
Vivado/Vitis HLS Backend¶
Author: Hongzheng Chen (hzchen@cs.cornell.edu)
In this tutorial, we will demonstrate how to leverage the Allo DSL to generate Vivado/Vitis HLS C++ code for FPGA.
Import Allo¶
First, we import the necessary packages.
import allo
from allo.ir.types import float32
import numpy as np
Algorithm Definition¶
We again define a general matrix multiplication (GEMM) in this tutorial. However, we will make some changes to demonstrate more features of the DSL.
We can define the constants as follows, which denotes the matrix sizes:
M, N, K = 32, 32, 32
Here, we define the main computation of the GEMM but use float32 as the
data type. Notice that users can easily leverage the previously defined arguments
(e.g., M, N, and K) to construct the matrices, and Allo will
automatically captures the global variables.
Since Allo has a strict type system, we need to be careful about the
data types of the variables. To initialize matrix C with all zeros, we
need to pass in a floating-point value 0.0 instead of an integer.
We also use the allo.reduction API to denote the reduction axis. The
reduction axis is the loop iterator that is used to accumulate the result.
In this example, we use k as the reduction axis, which means the
computation of C[i, j] will be accumulated along the k dimension.
This annotation is necessary for later optimizations, since Allo leverages
this information to generate correct intermediate buffers.
def gemm(A: float32[M, K], B: float32[K, N]) -> float32[M, N]:
C: float32[M, N] = 0.0
for i, j in allo.grid(M, N):
for k in allo.reduction(K):
C[i, j] += A[i, k] * B[k, j]
return C
Scalar-Vector Product for GEMM¶
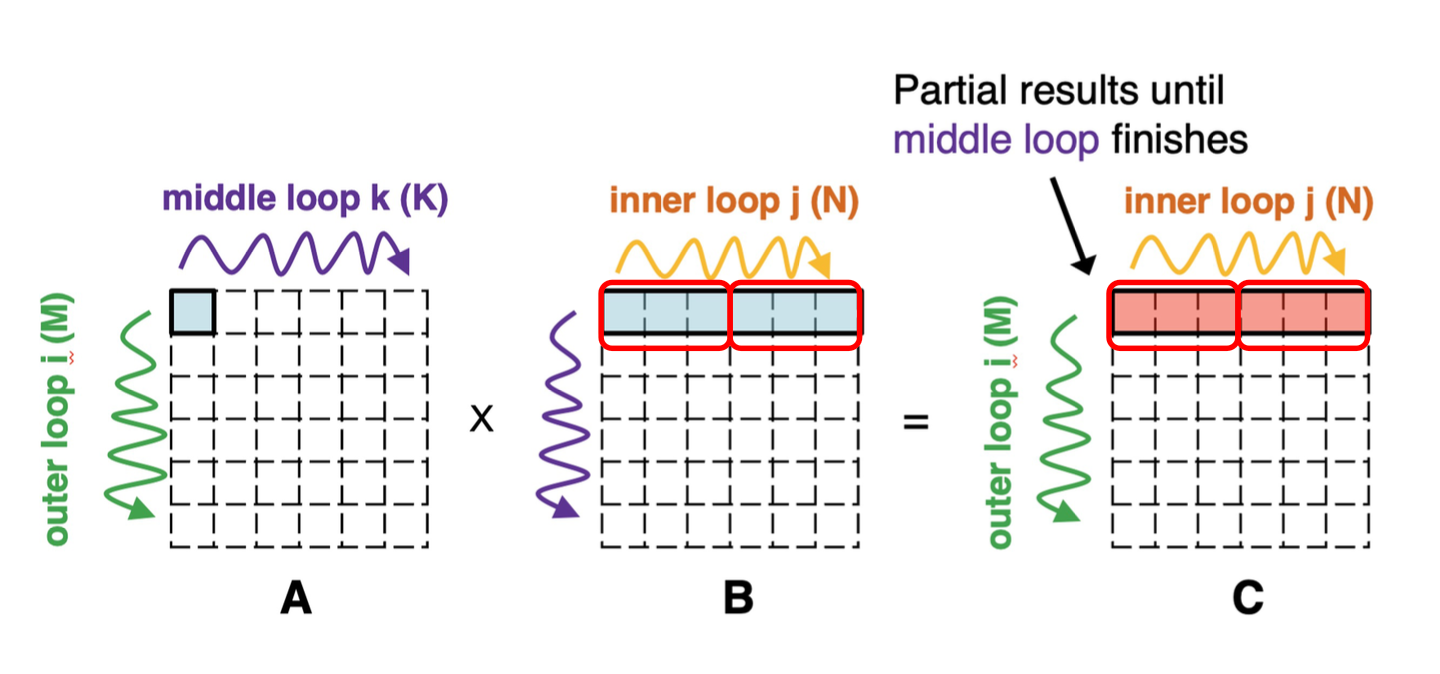
Next, we create a schedule for the GEMM and start to optimize the program. We try to implement the interleaving accumulation technique presented in this paper, which is also viewed as the scalar-vector product since it changes the computation order of the original dot-product.
Note
To get more rational of this technique, please refer to the above mentioned paper from Torsten Hoefler’s group.
s = allo.customize(gemm)
We first reorder the inner reduction loop with the middle loop. This is used to change the computation order of matrix multiplication.
s.reorder("k", "j")
print(s.module)
module {
func.func @gemm(%arg0: memref<32x32xf32>, %arg1: memref<32x32xf32>) -> memref<32x32xf32> attributes {itypes = "__", otypes = "_"} {
%alloc = memref.alloc() {name = "C"} : memref<32x32xf32>
%cst = arith.constant 0.000000e+00 : f32
linalg.fill ins(%cst : f32) outs(%alloc : memref<32x32xf32>)
affine.for %arg2 = 0 to 32 {
affine.for %arg3 = 0 to 32 {
affine.for %arg4 = 0 to 32 {
%0 = affine.load %arg0[%arg2, %arg3] {from = "A"} : memref<32x32xf32>
%1 = affine.load %arg1[%arg3, %arg4] {from = "B"} : memref<32x32xf32>
%2 = arith.mulf %0, %1 : f32
%3 = affine.load %alloc[%arg2, %arg4] {from = "C"} : memref<32x32xf32>
%4 = arith.addf %3, %2 : f32
affine.store %4, %alloc[%arg2, %arg4] {to = "C"} : memref<32x32xf32>
} {loop_name = "j"}
} {loop_name = "k", op_name = "S_k_0", reduction}
} {loop_name = "i", op_name = "S_i_j_0"}
return %alloc : memref<32x32xf32>
}
}
Note
This reordering seems to be easy, but it is impossible in the old Allo,
since the previous Allo directly generate reduction variables which make
the j loop becomes imperfect, while MLIR only supports reordering perfect
loops.
Next, we create a new buffer for the output tensor C.
We provide a .buffer_at() primitive for users to quickly create a new buffer
along a specific axis. Since Allo has attached all the tensors to the function,
we can directly use <schedule>.<tensor> to access a specific tensor in the schedule.
s.buffer_at(s.C, axis="i")
print(s.module)
module {
func.func @gemm(%arg0: memref<32x32xf32>, %arg1: memref<32x32xf32>) -> memref<32x32xf32> attributes {itypes = "__", otypes = "_"} {
%alloc = memref.alloc() {name = "C"} : memref<32x32xf32>
%cst = arith.constant 0.000000e+00 : f32
linalg.fill ins(%cst : f32) outs(%alloc : memref<32x32xf32>)
affine.for %arg2 = 0 to 32 {
%alloc_0 = memref.alloc() : memref<32xf32>
affine.for %arg3 = 0 to 32 {
affine.store %cst, %alloc_0[%arg3] : memref<32xf32>
} {buffer, loop_name = "j_init", pipeline_ii = 1 : i32}
affine.for %arg3 = 0 to 32 {
affine.for %arg4 = 0 to 32 {
%0 = affine.load %arg0[%arg2, %arg3] {from = "A"} : memref<32x32xf32>
%1 = affine.load %arg1[%arg3, %arg4] {from = "B"} : memref<32x32xf32>
%2 = arith.mulf %0, %1 : f32
%3 = affine.load %alloc_0[%arg4] : memref<32xf32>
%4 = arith.addf %3, %2 : f32
affine.store %4, %alloc_0[%arg4] : memref<32xf32>
} {loop_name = "j"}
} {loop_name = "k", op_name = "S_k_0", reduction}
affine.for %arg3 = 0 to 32 {
%0 = affine.load %alloc_0[%arg3] : memref<32xf32>
affine.store %0, %alloc[%arg2, %arg3] : memref<32x32xf32>
} {buffer, loop_name = "j_back", pipeline_ii = 1 : i32}
} {loop_name = "i", op_name = "S_i_j_0"}
return %alloc : memref<32x32xf32>
}
}
From the above generated code, we can see that Allo automatically
creates an intermediate buffer %1 for C and attach it inside the i loop.
Also two additional loop nested named j_init and j_back are created to
initialize and write the intermediate buffer back to output tensor.
Lastly, we pipeline the j loop in order to achieve the best performance.
s.pipeline("j")
print(s.module)
module {
func.func @gemm(%arg0: memref<32x32xf32>, %arg1: memref<32x32xf32>) -> memref<32x32xf32> attributes {itypes = "__", otypes = "_"} {
%alloc = memref.alloc() {name = "C"} : memref<32x32xf32>
%cst = arith.constant 0.000000e+00 : f32
linalg.fill ins(%cst : f32) outs(%alloc : memref<32x32xf32>)
affine.for %arg2 = 0 to 32 {
%alloc_0 = memref.alloc() : memref<32xf32>
affine.for %arg3 = 0 to 32 {
affine.store %cst, %alloc_0[%arg3] : memref<32xf32>
} {buffer, loop_name = "j_init", pipeline_ii = 1 : i32}
affine.for %arg3 = 0 to 32 {
affine.for %arg4 = 0 to 32 {
%0 = affine.load %arg0[%arg2, %arg3] {from = "A"} : memref<32x32xf32>
%1 = affine.load %arg1[%arg3, %arg4] {from = "B"} : memref<32x32xf32>
%2 = arith.mulf %0, %1 : f32
%3 = affine.load %alloc_0[%arg4] : memref<32xf32>
%4 = arith.addf %3, %2 : f32
affine.store %4, %alloc_0[%arg4] : memref<32xf32>
} {loop_name = "j", pipeline_ii = 1 : ui32}
} {loop_name = "k", op_name = "S_k_0", reduction}
affine.for %arg3 = 0 to 32 {
%0 = affine.load %alloc_0[%arg3] : memref<32xf32>
affine.store %0, %alloc[%arg2, %arg3] : memref<32x32xf32>
} {buffer, loop_name = "j_back", pipeline_ii = 1 : i32}
} {loop_name = "i", op_name = "S_i_j_0"}
return %alloc : memref<32x32xf32>
}
}
Codegen for Vivado/Vitis HLS¶
Similar to the CPU execution, we only need to change the target of the .build() function
in order to target different backends. Here, we use vhls as the target to generate
Vivado/Vitis HLS code, which will directly returns the generated code as a string.
code = s.build(target="vhls")
print(code)
//===------------------------------------------------------------*- C++ -*-===//
//
// Automatically generated file for High-level Synthesis (HLS).
//
//===----------------------------------------------------------------------===//
#include <algorithm>
#include <ap_axi_sdata.h>
#include <ap_fixed.h>
#include <ap_int.h>
#include <hls_math.h>
#include <hls_stream.h>
#include <hls_vector.h>
#include <math.h>
#include <stdint.h>
using namespace std;
/// This is top function.
void gemm(
float v0[32][32],
float v1[32][32],
float v2[32][32]
) { // L2
for (int v3 = 0; v3 < 32; v3++) { // L5
for (int v4 = 0; v4 < 32; v4++) { // L5
v2[v3][v4] = (float)0.000000; // L5
}
}
l_S_i_j_0_i: for (int i = 0; i < 32; i++) { // L6
float v6[32]; // L7
l_j_init: for (int j_init = 0; j_init < 32; j_init++) { // L8
#pragma HLS pipeline II=1
v6[j_init] = (float)0.000000; // L9
}
l_S_k_0_k: for (int k = 0; k < 32; k++) { // L11
l_j: for (int j = 0; j < 32; j++) { // L12
#pragma HLS pipeline II=1
float v10 = v0[i][k]; // L13
float v11 = v1[k][j]; // L14
float v12 = v10 * v11; // L15
float v13 = v6[j]; // L16
float v14 = v13 + v12; // L17
v6[j] = v14; // L18
}
}
l_j_back: for (int j_back = 0; j_back < 32; j_back++) { // L21
#pragma HLS pipeline II=1
float v16 = v6[j_back]; // L22
v2[i][j_back] = v16; // L23
}
}
}
We can see that the generated code preserves the same structure as the IR, and inserts necessary headers and pragmas for Vivado/Vitis HLS. The generated code can be directly passed to Vivado/Vitis HLS to generate RTL designs.
Note
Vivado HLS was the previous name of Vitis HLS (before 2020.1). The previous HLS code can still run on the latest Vitis HLS, but the performance of the generated RTL design and the estimated reports may be different, as the newer version of Vitis HLS provides better automatic optimizations.
We also provide an easy way to invoke Vitis HLS from Allo. Users can simply provide
the synthesis mode that are supported by Vitis HLS (e.g., sw_emu, hw_emu, and hw),
and the target project folder name. Allo will automatically generate
the HLS project and invoke the compiler to generate the RTL design.
Note
sw_emu: Software emulation mode, which is similar to C simulation that compiles the program using C compiler and runs it on the CPU. Depending on the size of your input data, this mode may take within one minute.hw_emu: Hardware emulation mode, which is similar to co-simulation that compiles the program into RTL design using HLS compiler and runs the RTL with the test bench on the FPGA emulator. Since it needs to go through the HLS synthesis flow, it may take several minutes to finish.hw: Hardware mode, which compiles the program into RTL design using HLS, goes through placement and routing, generates the bitstream, and finally executes on FPGA. This mode may take several hours to finish.
mod = s.build(target="vitis_hls", mode="hw_emu", project="gemm.prj")
After running the above instruction, we can see a gemm.prj folder is generated in the current directory:
host.cpp: The host (CPU) OpenCL code that invokes the generated accelerator.kernel.cpp: The generated accelerator code.Makefile: Defined some shorthands for compiling the project.
To generate the hardware design and see the performance estimation, we need to first
prepare the input data. Allo supports NumPy inputs even for hardware programs,
so we can just create two NumPy arrays np_A and np_B for inputs.
Since the C++ design cannot support returning a new array, we also need to
explicitly create an output array allo_C and pass it to the function.
Note
You need to configure the Vitis HLS and XRT environment before proceeding to the next step.
For Zhang group students, we have the Vitis environment configured on the server, so you can directly
source /work/shared/common/allo/vitis_2023.2_u280.sh to set up the environment, which
targets the AMD U280 FPGA board.
np_A = np.random.random((M, K)).astype(np.float32)
np_B = np.random.random((K, N)).astype(np.float32)
allo_C = np.zeros((M, N), dtype=np.float32)
mod(np_A, np_B, allo_C)
np.testing.assert_allclose(allo_C, np.matmul(np_A, np_B), rtol=1e-5, atol=1e-5)
After executing the above command, you can check the following report under gemm.prj/_x.hw_emu.xilinx_u250_gen3x16_xdma_4_1_202210_1/gemm/gemm/gemm/solution/syn/report/csynth.rpt.
+--------------------------------------------------+---------+-----------+----------+---------+------+----------+---------+---------+-------------+------------+-----+
| Modules | Latency | Latency | Iteration| | Trip | | | | | | |
| & Loops | (cycles)| (ns) | Latency | Interval| Count| Pipelined| BRAM | DSP | FF | LUT | URAM|
+--------------------------------------------------+---------+-----------+----------+---------+------+----------+---------+---------+-------------+------------+-----+
|+ gemm | 39934| 1.331e+05| -| 39935| -| no| 6 (~0%)| 5 (~0%)| 19074 (~0%)| 29069 (2%)| -|
| + gemm_Pipeline_VITIS_LOOP_44_1_VITIS_LOOP_45_2 | 1026| 3.420e+03| -| 1026| -| no| -| -| 36 (~0%)| 169 (~0%)| -|
| o VITIS_LOOP_44_1_VITIS_LOOP_45_2 | 1024| 3.413e+03| 2| 1| 1024| yes| -| -| -| -| -|
| o l_S_buf0_buf0_l_0_l_buf0_l_1 | 1025| 3.416e+03| 3| 1| 1024| yes| -| -| -| -| -|
| o l_S_buf1_buf1_l_0_l_buf1_l_1 | 1025| 3.416e+03| 3| 1| 1024| yes| -| -| -| -| -|
| o l_S_i_j_0_i | 35616| 1.187e+05| 1113| -| 32| no| -| -| -| -| -|
| + gemm_Pipeline_l_j_init | 34| 113.322| -| 34| -| no| -| -| 8 (~0%)| 50 (~0%)| -|
| o l_j_init | 32| 106.656| 1| 1| 32| yes| -| -| -| -| -|
| + gemm_Pipeline_l_S_k_0_k_l_j | 1039| 3.463e+03| -| 1039| -| no| -| 5 (~0%)| 759 (~0%)| 494 (~0%)| -|
| o l_S_k_0_k_l_j | 1037| 3.456e+03| 15| 1| 1024| yes| -| -| -| -| -|
| + gemm_Pipeline_l_j_back | 34| 113.322| -| 34| -| no| -| -| 15 (~0%)| 78 (~0%)| -|
| o l_j_back | 32| 106.656| 2| 1| 32| yes| -| -| -| -| -|
| o l_S_result2_result2_l_0_l_result2_l_1 | 1026| 3.420e+03| 4| 1| 1024| yes| -| -| -| -| -|
+--------------------------------------------------+---------+-----------+----------+---------+------+----------+---------+---------+-------------+------------+-----+
From the above output, we can clearly see that all the loops inside the GEMM kernel (marked as o) are pipelined
with Initiation Interval (II) equal to 1. You can also find more detailed information under the report folder.
On-board Execution¶
After optimizing the design and make sure everything works correctly,
we can push the generated RTL design to the backend synthesis flow to generate
the bitstream for FPGA. In Allo, we can directly change the target to hw
to launch the backend synthesis job. It may take several hours to generate the final
bitstream, so it would be better to run it using tmux.
mod = s.build(target="vitis_hls", mode="hw", project="gemm.prj")
mod(np_A, np_B, allo_C)
np.testing.assert_allclose(allo_C, np.matmul(np_A, np_B), rtol=1e-5, atol=1e-5)
Finally, you should be able to see the generated bitstream .xclbin under the gemm.prj/build_dir.hw.xilinx_u280_gen3x16_xdma_1_202211_1 folder
(actual board name may be different), and the above test should pass.
To get more detailed information on the resource usage and performance of the generated design, you can check the following files:
gemm.prj/build_dir.hw.xilinx_u280_gen3x16_xdma_1_202211_1/gemm.xclbin: The generated bitstream.gemm.prj/build_dir.hw.xilinx_u280_gen3x16_xdma_1_202211_1/gemm.link.xclbin.info: Frequency of the actual design, which can be found inDATA_CLK. By default, it is 300MHz.gemm.prj/_x.hw.xilinx_u280_gen3x16_xdma_1_202211_1/reports/gemm/hls_reports/gemm_csynth.rpt: The HLS synthesis report.gemm.prj/_x.hw.xilinx_u280_gen3x16_xdma_1_202211_1/reports/link/imp/impl_1_full_util_routed.rpt: The full utilization report after placement and routing. You can find the following resource usage:LUT:
1. CLB Logic -- CLB LUTsFF:
1. CLB Logic -- CLB Registers -- Register as Flip FlopBRAM:
3. BLOCKRAM -- Block RAM TileDSP:
4. ARITHMETIC -- DSPs
gemm.prj/_x.hw.xilinx_u280_gen3x16_xdma_1_202211_1/reports/link/imp/impl_1_slr_util_routed.rpt: The per SLR utilization report after placement and routing.gemm.prj/_x.hw.xilinx_u280_gen3x16_xdma_1_202211_1/logs/gemm/gemm_vitis_hls.log: The log file of the Vitis HLS.gemm.prj/_x.hw.xilinx_u280_gen3x16_xdma_1_202211_1/logs/link/v++.log: The log file of the Vivado backend synthesis.
Total running time of the script: (0 minutes 0.135 seconds)