Note
Click here to download the full example code
Memory Customization¶
Author: Yi-Hsiang Lai (seanlatias@github)
In this tutorial, we demonstrate how memory customization works in HeteroCL.
import heterocl as hcl
import numpy as np
Memory Customization in HeteroCL¶
There are two types of memory customization in HeteroCL. The first one is
similar to what we have seen in
Compute Customization, where we demonstrate some
primitives that will be synthesized as pragmas. An example of such primitive
is partition. Following is an example. Note that the primitive is
directly applied on the schedule instead of a stage. This is because we are
modifying the property of a tensor.
hcl.init()
A = hcl.placeholder((10, 10), "A")
def kernel(A):
return hcl.compute(A.shape, lambda x, y: A[x][y] + 1, "B")
s = hcl.create_schedule(A, kernel)
s.partition(A)
print(hcl.lower(s))
#map = affine_map<(d0, d1) -> (d0, d1, 0, 0)>
module {
func.func @top(%arg0: memref<10x10xi32, #map>) -> memref<10x10xi32> attributes {itypes = "s", otypes = "s"} {
%0 = memref.alloc() {name = "B"} : memref<10x10xi32>
affine.for %arg1 = 0 to 10 {
affine.for %arg2 = 0 to 10 {
%1 = affine.load %arg0[%arg1, %arg2] {from = "A"} : memref<10x10xi32, #map>
%c1_i32 = arith.constant 1 : i32
%2 = arith.extsi %1 : i32 to i33
%3 = arith.extsi %c1_i32 : i32 to i33
%4 = arith.addi %2, %3 : i33
%5 = arith.trunci %4 : i33 to i32
affine.store %5, %0[%arg1, %arg2] {to = "B"} : memref<10x10xi32>
} {loop_name = "y"}
} {loop_name = "x", op_name = "B"}
return %0 : memref<10x10xi32>
}
}
In the IR, we should see a line that annotates tensor A to be
partitioned completely.
Note
For more information, please see
heterocl.schedule.Schedule.partition
Another example is to reshape a tensor. This is helpful when we combine
partitioning with loop titling. In this example, we split the inner axis
y and also reshape the output tensor B. After that, we pipeline
the middle axis yo and partition the output tensor accordingly. Note
that the reshape primitive cannot be applied to the input tensors.
hcl.init()
s = hcl.create_schedule(A, kernel)
yo, yi = s[kernel.B].split(kernel.B.axis[1], 5)
s[kernel.B].pipeline(yo)
s.reshape(kernel.B, (10, 2, 5))
s.partition(kernel.B, dim=3)
print(hcl.build(s, target="vhls"))
//===------------------------------------------------------------*- C++ -*-===//
//
// Automatically generated file for High-level Synthesis (HLS).
//
//===----------------------------------------------------------------------===//
#include <algorithm>
#include <ap_axi_sdata.h>
#include <ap_fixed.h>
#include <ap_int.h>
#include <hls_math.h>
#include <hls_stream.h>
#include <math.h>
#include <stdint.h>
using namespace std;
void top(
int32_t v0[10][10],
int32_t v1[10][2][5]
) { // L28
#pragma HLS array_partition variable=v1 complete dim=3
l_B_x: for (int x = 0; x < 10; x++) { // L472
l_y_outer: for (int y_outer = 0; y_outer < 2; y_outer++) { // L472
#pragma HLS pipeline II=1
l_y_inner: for (int y_inner = 0; y_inner < 5; y_inner++) { // L472
int v5 = (y_inner + (y_outer * 5)); // L472
int32_t v6 = v0[x][v5]; // L28
ap_int<33> v7 = v6; // L472
ap_int<33> v8 = 1; // L472
ap_int<33> v9 = v7 + v8; // L28
int32_t v10 = v9; // L472
v1[(x + ((v5 / 5) / 2))][((v5 / 5) % 2)][(v5 % 5)] = v10; // L472
}
}
}
}
Data Reuse in HeteroCL¶
The other type of memory customization primitives involves the introduction of allocation of new memory buffers. An example is data reuse. The idea of data reuse is to reduce the number of accesses to a tensor by introducing an intermediate buffer that holds the values being reused across different iterations. This finally leads to better performance in hardware.
Example: 2D Convolution¶
To demonstrate this, we use the computation of 2D convolution as an example. Let’s see how we can define 2D convolution in HeteroCL.
hcl.init()
A = hcl.placeholder((6, 6), "A")
F = hcl.placeholder((3, 3), "F")
def kernel(A, F):
r = hcl.reduce_axis(0, 3)
c = hcl.reduce_axis(0, 3)
return hcl.compute(
(4, 4), lambda y, x: hcl.sum(A[y + r, x + c] * F[r, c], axis=[r, c]), "B"
)
s = hcl.create_schedule([A, F], kernel)
print(hcl.lower(s))
module {
func.func @top(%arg0: memref<6x6xi32>, %arg1: memref<3x3xi32>) -> memref<4x4xi32> attributes {itypes = "ss", otypes = "s"} {
%0 = memref.alloc() {name = "B"} : memref<4x4xi32>
affine.for %arg2 = 0 to 4 {
affine.for %arg3 = 0 to 4 {
%1 = memref.alloc() {name = "sum"} : memref<1xi32>
%c0_i32 = arith.constant 0 : i32
affine.store %c0_i32, %1[0] {to = "sum"} : memref<1xi32>
affine.for %arg4 = 0 to 3 {
affine.for %arg5 = 0 to 3 {
%true = arith.constant true
scf.if %true {
%3 = affine.load %arg0[%arg2 + %arg4, %arg3 + %arg5] {from = "A"} : memref<6x6xi32>
%4 = affine.load %arg1[%arg4, %arg5] {from = "F"} : memref<3x3xi32>
%5 = arith.extsi %3 : i32 to i64
%6 = arith.extsi %4 : i32 to i64
%7 = arith.muli %5, %6 : i64
%8 = affine.load %1[0] {from = "sum"} : memref<1xi32>
%9 = arith.extsi %7 : i64 to i65
%10 = arith.extsi %8 : i32 to i65
%11 = arith.addi %9, %10 : i65
%12 = arith.trunci %11 : i65 to i32
affine.store %12, %1[0] {to = "sum"} : memref<1xi32>
}
} {loop_name = "r_1", reduction}
} {loop_name = "r_0", reduction}
%2 = affine.load %1[0] {from = "sum"} : memref<1xi32>
affine.store %2, %0[%arg2, %arg3] {to = "B"} : memref<4x4xi32>
} {loop_name = "x"}
} {loop_name = "y", op_name = "B"}
return %0 : memref<4x4xi32>
}
}
In the above example, we convolve the input tensor A with a filter F.
Then, we store the output in tensor B. Note that the output shape is
different from the shape of the input tensor. Let’s give some real inputs.
hcl_A = hcl.asarray(np.random.randint(0, 10, A.shape))
hcl_F = hcl.asarray(np.random.randint(0, 10, F.shape))
hcl_B = hcl.asarray(np.zeros((4, 4)))
f = hcl.build(s)
f(hcl_A, hcl_F, hcl_B)
print("Input:")
print(hcl_A)
print("Filter:")
print(hcl_F)
print("Output:")
print(hcl_B)
Input:
array([[0, 5, 9, 2, 7, 3],
[1, 1, 2, 6, 9, 3],
[4, 8, 3, 9, 8, 4],
[0, 4, 6, 3, 2, 9],
[5, 8, 8, 5, 5, 3],
[9, 3, 8, 7, 5, 8]])
Filter:
array([[4, 6, 3],
[0, 6, 2],
[1, 7, 6]])
Output:
array([[145, 187, 237, 208],
[134, 134, 180, 214],
[218, 213, 185, 184],
[184, 220, 175, 177]])
To analyze the data reuse, let’s take a closer look to the generated IR.
To begin with, we can see that in two consecutive iterations of x (i.e.,
the inner loop), there are 6 pixels that are overlapped, as illustrated in
the figure below. Without any optimization, we are reading 9 values from
the input for each iteration.

Introduce Data Reuse: Window Buffer¶
To reuse the overlapped pixels, we can introduce a reuse buffer. Since the
filter moves like a window, we call the buffer a window buffer WB. The
window buffers stores the reused pixels and also the new pixels that will
be used in the current iteration. For each iteration, to update the values
inside the window buffer, the last two columns, in this case, shift left.
After that, the last column is replaced with the pixels read from the
input. Now, we only read 3 values from the input for each iteration.
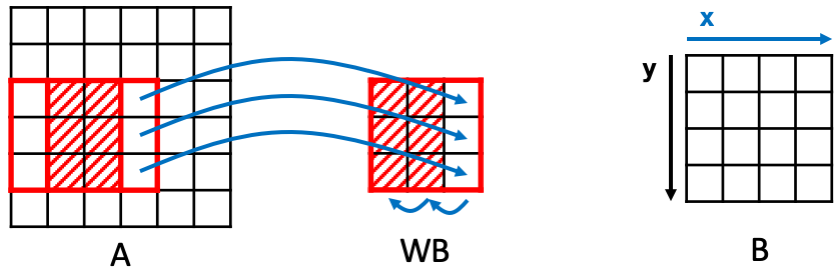
To introduce such reuse buffers in HeteroCL, we use the API reuse_at.
The first argument is the tensor whose values will be reused. The
second argument is the output stage that reuses the values of the
tensor. The reason why we need to specify this is because we may have
multiple stages reusing the values from the same input tensor. The third
argument is the desired axis to be reused. It must be the output axis.
Finally, we can specify the name of the reuse buffer. The API returns
a new tensor.
s_x = hcl.create_schedule([A, F], kernel)
WB = s_x.reuse_at(A, s_x[kernel.B], kernel.B.axis[1], "WB")
print(hcl.lower(s_x))
#set = affine_set<(d0) : (d0 - 2 >= 0)>
module {
func.func @top(%arg0: memref<6x6xi32>, %arg1: memref<3x3xi32>) -> memref<4x4xi32> attributes {itypes = "ss", otypes = "s"} {
%0 = memref.alloc() {name = "B"} : memref<4x4xi32>
%1 = memref.alloc() {name = "B_reuse_1"} : memref<3x3xi32>
affine.for %arg2 = 0 to 4 {
affine.for %arg3 = 0 to 6 {
affine.for %arg4 = 0 to 3 {
%2 = affine.load %1[%arg4, 1] : memref<3x3xi32>
affine.store %2, %1[%arg4, 0] : memref<3x3xi32>
%3 = affine.load %1[%arg4, 2] : memref<3x3xi32>
affine.store %3, %1[%arg4, 1] : memref<3x3xi32>
%4 = affine.load %arg0[%arg2 + %arg4, %arg3] : memref<6x6xi32>
affine.store %4, %1[%arg4, 2] : memref<3x3xi32>
} {spatial}
affine.if #set(%arg3) {
%2 = memref.alloc() {name = "sum"} : memref<1xi32>
%c0_i32 = arith.constant 0 : i32
affine.store %c0_i32, %2[0] {to = "sum"} : memref<1xi32>
affine.for %arg4 = 0 to 3 {
affine.for %arg5 = 0 to 3 {
%true = arith.constant true
scf.if %true {
%4 = affine.load %1[%arg4, %arg5] : memref<3x3xi32>
%5 = affine.load %arg1[%arg4, %arg5] {from = "F"} : memref<3x3xi32>
%6 = arith.extsi %4 : i32 to i64
%7 = arith.extsi %5 : i32 to i64
%8 = arith.muli %6, %7 : i64
%9 = affine.load %2[0] {from = "sum"} : memref<1xi32>
%10 = arith.extsi %8 : i64 to i65
%11 = arith.extsi %9 : i32 to i65
%12 = arith.addi %10, %11 : i65
%13 = arith.trunci %12 : i65 to i32
affine.store %13, %2[0] {to = "sum"} : memref<1xi32>
}
} {loop_name = "r_1", reduction}
} {loop_name = "r_0", reduction}
%3 = affine.load %2[0] {from = "sum"} : memref<1xi32>
affine.store %3, %0[%arg2, %arg3 - 2] : memref<4x4xi32>
}
} {loop_name = "x"}
} {loop_name = "y", op_name = "B"}
return %0 : memref<4x4xi32>
}
}
In the printed IR, you should be able to see a buffer WB with size
(3, 3) being allocated. Moreover, in the produce WB scope, you should
see the update algorithm described above. Now let’s test the function again.
hcl_Bx = hcl.asarray(np.zeros((4, 4)))
f = hcl.build(s_x)
f(hcl_A, hcl_F, hcl_Bx)
print("Output without WB:")
print(hcl_B)
print("Output with WB:")
print(hcl_Bx)
Output without WB:
array([[145, 187, 237, 208],
[134, 134, 180, 214],
[218, 213, 185, 184],
[184, 220, 175, 177]])
Output with WB:
array([[145, 187, 237, 208],
[134, 134, 180, 214],
[218, 213, 185, 184],
[184, 220, 175, 177]])
You should see the same results with and without the window buffer.
Reuse at a Different Dimension: Linebuffer¶
Similarly, we can create a reuse buffer for two consecutive iterations of
y. In this case, in each iteration of y, we read an entire row from
input A. Meanwhile, we update the reuse buffer by shifting up. Since it
reads an entire line at a time, we call it a linebuffer LB. The
operation is illustrated in the figure below.
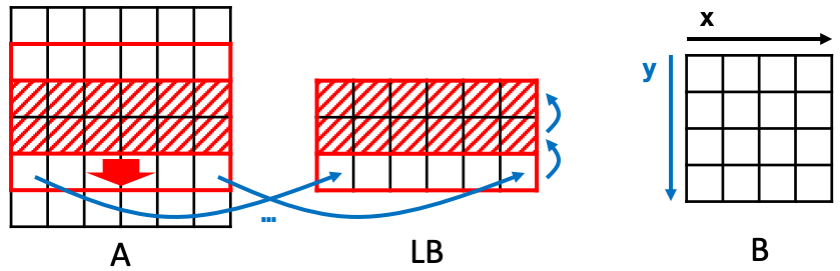
Similar to the window buffer, we can introduce the linebuffer in HeteroCL by
using a single reuse_at API. We show the code below.
s_y = hcl.create_schedule([A, F], kernel)
LB = s_y.reuse_at(A, s_y[kernel.B], kernel.B.axis[0], "LB")
print(hcl.lower(s_y))
hcl_By = hcl.asarray(np.zeros((4, 4)))
f = hcl.build(s_y)
f(hcl_A, hcl_F, hcl_By)
print("Output without LB:")
print(hcl_B)
print("Output with LB:")
print(hcl_By)
#set = affine_set<(d0) : (d0 - 2 >= 0)>
module {
func.func @top(%arg0: memref<6x6xi32>, %arg1: memref<3x3xi32>) -> memref<4x4xi32> attributes {itypes = "ss", otypes = "s"} {
%0 = memref.alloc() {name = "B"} : memref<4x4xi32>
%1 = memref.alloc() {name = "B_reuse_0"} : memref<3x6xi32>
affine.for %arg2 = 0 to 6 {
affine.for %arg3 = 0 to 6 {
%2 = affine.load %1[1, %arg3] : memref<3x6xi32>
affine.store %2, %1[0, %arg3] : memref<3x6xi32>
%3 = affine.load %1[2, %arg3] : memref<3x6xi32>
affine.store %3, %1[1, %arg3] : memref<3x6xi32>
%4 = affine.load %arg0[%arg2, %arg3] : memref<6x6xi32>
affine.store %4, %1[2, %arg3] : memref<3x6xi32>
} {spatial}
affine.if #set(%arg2) {
affine.for %arg3 = 0 to 4 {
%2 = memref.alloc() {name = "sum"} : memref<1xi32>
%c0_i32 = arith.constant 0 : i32
affine.store %c0_i32, %2[0] {to = "sum"} : memref<1xi32>
affine.for %arg4 = 0 to 3 {
affine.for %arg5 = 0 to 3 {
%true = arith.constant true
scf.if %true {
%4 = affine.load %1[%arg4, %arg3 + %arg5] : memref<3x6xi32>
%5 = affine.load %arg1[%arg4, %arg5] {from = "F"} : memref<3x3xi32>
%6 = arith.extsi %4 : i32 to i64
%7 = arith.extsi %5 : i32 to i64
%8 = arith.muli %6, %7 : i64
%9 = affine.load %2[0] {from = "sum"} : memref<1xi32>
%10 = arith.extsi %8 : i64 to i65
%11 = arith.extsi %9 : i32 to i65
%12 = arith.addi %10, %11 : i65
%13 = arith.trunci %12 : i65 to i32
affine.store %13, %2[0] {to = "sum"} : memref<1xi32>
}
} {loop_name = "r_1", reduction}
} {loop_name = "r_0", reduction}
%3 = affine.load %2[0] {from = "sum"} : memref<1xi32>
affine.store %3, %0[%arg2 - 2, %arg3] : memref<4x4xi32>
} {loop_name = "x"}
}
} {loop_name = "y", op_name = "B"}
return %0 : memref<4x4xi32>
}
}
Output without LB:
array([[145, 187, 237, 208],
[134, 134, 180, 214],
[218, 213, 185, 184],
[184, 220, 175, 177]])
Output with LB:
array([[145, 187, 237, 208],
[134, 134, 180, 214],
[218, 213, 185, 184],
[184, 220, 175, 177]])
Note that the difference between WB and LB is the we reuse at different
axes. We can also see from the printed IR that the allocated size is larger,
which is the same as illustrated in the figure above. In this case, we read
6 pixels from the input for each iteration of y, which means we read 1
pixel for each iteration of x effectively. Namely, this is not true
in terms of hardware execution. Can we do even better?
Combine Window Buffer and Linebuffer¶
We do not need to restrict ourselves to reuse at a single dimension. Since we have data reuse in both dimension, we can reuse both. In this case, we generate both a linebuffer and a window buffer. Let’s take a look at the figure first.
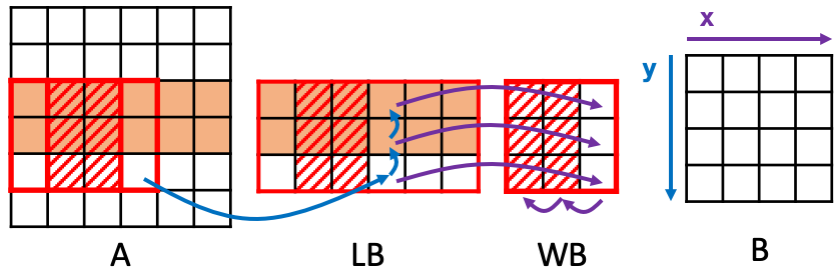
What happens here is that, we first update the linebuffer (blue arrows),
then we update the window buffer (purple arrows). More precisely, for each
iteration of x, we read 1 pixel from input ``A``. We simultaneously
shift up the linebffer. After we update the linebuffer, we go on update the
window buffer by reading pixels updated in the linebuffer. Then we shift the
window buffer. To describe such behavior in HeteroCL is very easy. We only
need to apply reuse_at twice. We just need to specify the corresponding
reuse tensors and the reuse axes. In this case, the linebuffer reuses the
pixels from the input A while the window buffer reuses from the
linebuffer. Following we show the code and its IR.
s_xy = hcl.create_schedule([A, F], kernel)
LB = s_xy.reuse_at(A, s_xy[kernel.B], kernel.B.axis[0], "LB")
WB = s_xy.reuse_at(LB, s_xy[kernel.B], kernel.B.axis[1], "WB")
print(hcl.lower(s_xy))
hcl_Bxy = hcl.asarray(np.zeros((4, 4)))
f = hcl.build(s_xy)
f(hcl_A, hcl_F, hcl_Bxy)
print("Output without reuse buffers:")
print(hcl_B)
print("Output with reuse buffers:")
print(hcl_Bxy)
#set = affine_set<(d0) : (d0 - 2 >= 0)>
module {
func.func @top(%arg0: memref<6x6xi32>, %arg1: memref<3x3xi32>) -> memref<4x4xi32> attributes {itypes = "ss", otypes = "s"} {
%0 = memref.alloc() {name = "B"} : memref<4x4xi32>
%1 = memref.alloc() {name = "B_reuse_0"} : memref<3x6xi32>
%2 = memref.alloc() {name = "B_reuse_1"} : memref<3x3xi32>
affine.for %arg2 = 0 to 6 {
affine.for %arg3 = 0 to 6 {
%3 = affine.load %1[1, %arg3] : memref<3x6xi32>
affine.store %3, %1[0, %arg3] : memref<3x6xi32>
%4 = affine.load %1[2, %arg3] : memref<3x6xi32>
affine.store %4, %1[1, %arg3] : memref<3x6xi32>
%5 = affine.load %arg0[%arg2, %arg3] : memref<6x6xi32>
affine.store %5, %1[2, %arg3] : memref<3x6xi32>
affine.if #set(%arg2) {
affine.for %arg4 = 0 to 3 {
%6 = affine.load %2[%arg4, 1] : memref<3x3xi32>
affine.store %6, %2[%arg4, 0] : memref<3x3xi32>
%7 = affine.load %2[%arg4, 2] : memref<3x3xi32>
affine.store %7, %2[%arg4, 1] : memref<3x3xi32>
%8 = affine.load %1[%arg4, %arg3] : memref<3x6xi32>
affine.store %8, %2[%arg4, 2] : memref<3x3xi32>
} {spatial}
affine.if #set(%arg3) {
%6 = memref.alloc() {name = "sum"} : memref<1xi32>
%c0_i32 = arith.constant 0 : i32
affine.store %c0_i32, %6[0] {to = "sum"} : memref<1xi32>
affine.for %arg4 = 0 to 3 {
affine.for %arg5 = 0 to 3 {
%true = arith.constant true
scf.if %true {
%8 = affine.load %2[%arg4, %arg5] : memref<3x3xi32>
%9 = affine.load %arg1[%arg4, %arg5] {from = "F"} : memref<3x3xi32>
%10 = arith.extsi %8 : i32 to i64
%11 = arith.extsi %9 : i32 to i64
%12 = arith.muli %10, %11 : i64
%13 = affine.load %6[0] {from = "sum"} : memref<1xi32>
%14 = arith.extsi %12 : i64 to i65
%15 = arith.extsi %13 : i32 to i65
%16 = arith.addi %14, %15 : i65
%17 = arith.trunci %16 : i65 to i32
affine.store %17, %6[0] {to = "sum"} : memref<1xi32>
}
} {loop_name = "r_1", reduction}
} {loop_name = "r_0", reduction}
%7 = affine.load %6[0] {from = "sum"} : memref<1xi32>
affine.store %7, %0[%arg2 - 2, %arg3 - 2] : memref<4x4xi32>
}
}
} {loop_name = "x"}
} {loop_name = "y", op_name = "B"}
return %0 : memref<4x4xi32>
}
}
Output without reuse buffers:
array([[145, 187, 237, 208],
[134, 134, 180, 214],
[218, 213, 185, 184],
[184, 220, 175, 177]])
Output with reuse buffers:
array([[145, 187, 237, 208],
[134, 134, 180, 214],
[218, 213, 185, 184],
[184, 220, 175, 177]])
We can see from the IR that the allocation sizes are indeed as expected.
Further Optimization¶
To further optimize the design, we need to think more carefully. For each
iteration of x, there are three pixels in LB that are being read/write
simultaneously. Thus, to maximize the memory bandwidth, we need to partition
LB in the row direction. For WB, all pixels are updated at the same time.
Therefore, we need to partition the whole WB completely. Finally, we can
pipeline the whole design. Don’t forget that we also need to partition the
filter F.
s_final = hcl.create_schedule([A, F], kernel)
LB = s_final.reuse_at(A, s_final[kernel.B], kernel.B.axis[0], "LB")
WB = s_final.reuse_at(LB, s_final[kernel.B], kernel.B.axis[1], "WB")
s_final.partition(LB, dim=1)
s_final.partition(WB)
s_final.partition(F)
s_final[kernel.B].pipeline(kernel.B.axis[1])
print(hcl.lower(s_final))
#map0 = affine_map<(d0, d1) -> (d0, d1, 0, 0)>
#map1 = affine_map<(d0, d1) -> (d0, 0, 0, d1)>
#set = affine_set<(d0) : (d0 - 2 >= 0)>
module {
func.func @top(%arg0: memref<6x6xi32>, %arg1: memref<3x3xi32, #map0>) -> memref<4x4xi32> attributes {itypes = "ss", otypes = "s"} {
%0 = memref.alloc() {name = "B"} : memref<4x4xi32>
%1 = memref.alloc() {name = "B_reuse_0"} : memref<3x6xi32, #map1>
%2 = memref.alloc() {name = "B_reuse_1"} : memref<3x3xi32, #map0>
affine.for %arg2 = 0 to 6 {
affine.for %arg3 = 0 to 6 {
%3 = affine.load %1[1, %arg3] : memref<3x6xi32, #map1>
affine.store %3, %1[0, %arg3] : memref<3x6xi32, #map1>
%4 = affine.load %1[2, %arg3] : memref<3x6xi32, #map1>
affine.store %4, %1[1, %arg3] : memref<3x6xi32, #map1>
%5 = affine.load %arg0[%arg2, %arg3] : memref<6x6xi32>
affine.store %5, %1[2, %arg3] : memref<3x6xi32, #map1>
affine.if #set(%arg2) {
affine.for %arg4 = 0 to 3 {
%6 = affine.load %2[%arg4, 1] : memref<3x3xi32, #map0>
affine.store %6, %2[%arg4, 0] : memref<3x3xi32, #map0>
%7 = affine.load %2[%arg4, 2] : memref<3x3xi32, #map0>
affine.store %7, %2[%arg4, 1] : memref<3x3xi32, #map0>
%8 = affine.load %1[%arg4, %arg3] : memref<3x6xi32, #map1>
affine.store %8, %2[%arg4, 2] : memref<3x3xi32, #map0>
} {spatial}
affine.if #set(%arg3) {
%6 = memref.alloc() {name = "sum"} : memref<1xi32>
%c0_i32 = arith.constant 0 : i32
affine.store %c0_i32, %6[0] {to = "sum"} : memref<1xi32>
affine.for %arg4 = 0 to 3 {
affine.for %arg5 = 0 to 3 {
%true = arith.constant true
scf.if %true {
%8 = affine.load %2[%arg4, %arg5] : memref<3x3xi32, #map0>
%9 = affine.load %arg1[%arg4, %arg5] {from = "F"} : memref<3x3xi32, #map0>
%10 = arith.extsi %8 : i32 to i64
%11 = arith.extsi %9 : i32 to i64
%12 = arith.muli %10, %11 : i64
%13 = affine.load %6[0] {from = "sum"} : memref<1xi32>
%14 = arith.extsi %12 : i64 to i65
%15 = arith.extsi %13 : i32 to i65
%16 = arith.addi %14, %15 : i65
%17 = arith.trunci %16 : i65 to i32
affine.store %17, %6[0] {to = "sum"} : memref<1xi32>
}
} {loop_name = "r_1", reduction}
} {loop_name = "r_0", reduction}
%7 = affine.load %6[0] {from = "sum"} : memref<1xi32>
affine.store %7, %0[%arg2 - 2, %arg3 - 2] : memref<4x4xi32>
}
}
} {loop_name = "x", pipeline_ii = 1 : i32}
} {loop_name = "y", op_name = "B"}
return %0 : memref<4x4xi32>
}
}
Finally, we can generate the HLS code and see if the II is indeed 1.
f = hcl.build(s_final, target="vhls")
Following is a sample report from Vivado_HLS.
+ Latency (clock cycles):
* Summary:
+-----+-----+-----+-----+---------+
| Latency | Interval | Pipeline|
| min | max | min | max | Type |
+-----+-----+-----+-----+---------+
| 42| 42| 43| 43| none |
+-----+-----+-----+-----+---------+
+ Detail:
* Instance:
N/A
* Loop:
+----------+-----+-----+----------+-----------+-----------+------+----------+
| | Latency | Iteration| Initiation Interval | Trip | |
| Loop Name| min | max | Latency | achieved | target | Count| Pipelined|
+----------+-----+-----+----------+-----------+-----------+------+----------+
|- Loop 1 | 40| 40| 6| 1| 1| 36| yes |
+----------+-----+-----+----------+-----------+-----------+------+----------+
Limitations¶
Following we list the limitations of using reuse buffers in HeteroCL.
We do not accept non-linear index patterns, e.g.,
y*y+c,y*(y+c)The stride is not one, e.g.,
2*y+cThere is no overlapped pixel between two consecutive iterations of the specified axis, e.g.,
[x+r, y]and reusey
More Examples: 2D Image Blur¶
HeteroCL is also able to infer reuse buffers for explicit reduction
operations. Namely, instead of using hcl.sum, we can expand the compute
patterns. Following is an example of 2D blur.
hcl.init()
A = hcl.placeholder((10, 10), "A")
def kernel_blur(A):
return hcl.compute(
(8, 8), lambda y, x: A[y, x] + A[y + 1, x + 1] + A[y + 2, x + 2], "B"
)
s_blur = hcl.create_schedule(A, kernel_blur)
B = kernel_blur.B
RB_y = s_blur.reuse_at(A, s_blur[B], B.axis[0], "RB_y")
RB_x = s_blur.reuse_at(RB_y, s_blur[B], B.axis[1], "RB_x")
print(hcl.lower(s_blur))
#set = affine_set<(d0) : (d0 - 2 >= 0)>
module {
func.func @top(%arg0: memref<10x10xi32>) -> memref<8x8xi32> attributes {itypes = "s", otypes = "s"} {
%0 = memref.alloc() {name = "B"} : memref<8x8xi32>
%1 = memref.alloc() {name = "B_reuse_0"} : memref<3x10xi32>
%2 = memref.alloc() {name = "B_reuse_1"} : memref<3x3xi32>
affine.for %arg1 = 0 to 10 {
affine.for %arg2 = 0 to 10 {
%3 = affine.load %1[1, %arg2] : memref<3x10xi32>
affine.store %3, %1[0, %arg2] : memref<3x10xi32>
%4 = affine.load %1[2, %arg2] : memref<3x10xi32>
affine.store %4, %1[1, %arg2] : memref<3x10xi32>
%5 = affine.load %arg0[%arg1, %arg2] : memref<10x10xi32>
affine.store %5, %1[2, %arg2] : memref<3x10xi32>
affine.if #set(%arg1) {
affine.for %arg3 = 0 to 3 {
%6 = affine.load %2[%arg3, 1] : memref<3x3xi32>
affine.store %6, %2[%arg3, 0] : memref<3x3xi32>
%7 = affine.load %2[%arg3, 2] : memref<3x3xi32>
affine.store %7, %2[%arg3, 1] : memref<3x3xi32>
%8 = affine.load %1[%arg3, %arg2] : memref<3x10xi32>
affine.store %8, %2[%arg3, 2] : memref<3x3xi32>
} {spatial}
affine.if #set(%arg2) {
%6 = affine.load %2[0, 0] : memref<3x3xi32>
%7 = affine.load %2[1, 1] : memref<3x3xi32>
%8 = arith.extsi %6 : i32 to i33
%9 = arith.extsi %7 : i32 to i33
%10 = arith.addi %8, %9 : i33
%11 = affine.load %2[2, 2] : memref<3x3xi32>
%12 = arith.extsi %10 : i33 to i34
%13 = arith.extsi %11 : i32 to i34
%14 = arith.addi %12, %13 : i34
%15 = arith.trunci %14 : i34 to i32
affine.store %15, %0[%arg1 - 2, %arg2 - 2] : memref<8x8xi32>
}
}
} {loop_name = "x"}
} {loop_name = "y", op_name = "B"}
return %0 : memref<8x8xi32>
}
}
Total running time of the script: ( 0 minutes 0.370 seconds)